Knowledge Distillation, aka. Teacher-Student Model
With the release of large models in the last few years, from GPT-3 to Megatron, I keep pondering how to experiment and use these models for a specific use case. These models are trained on massive corpuses of data (100+ GBs) with billions of parameters. Training or performing inference using such a model requires heavy computing and cost.
Knowledge Distillation
To overcome the above challenges, there are techniques developed to transfer the knowledge learnt by a larger model (teacher) and instil it into a smaller model (student).
Here the knowledge refers to parameters learnt during model training. This whole concept is called “Knowledge Distillation.” Knowledge distillation in machine learning refers to transferring knowledge from a teacher to a student model.
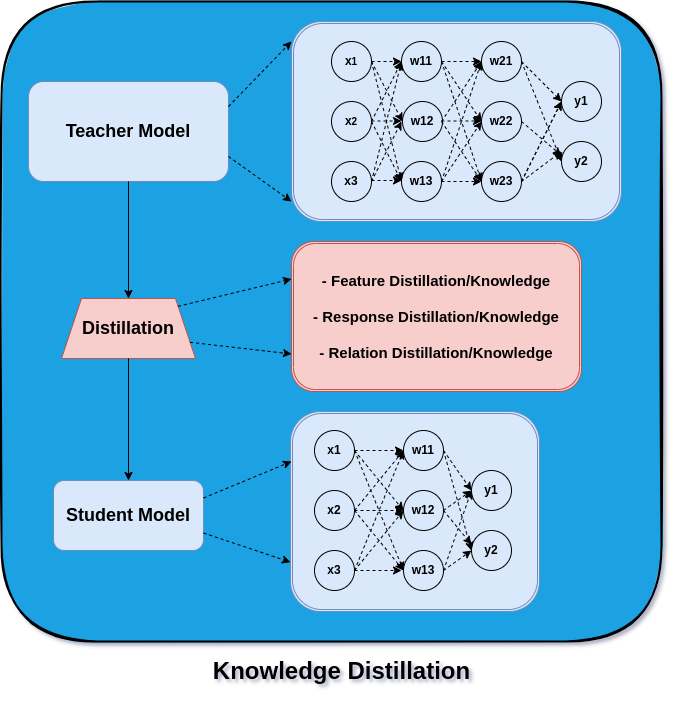
Knowledge Distillation
We can understand this teacher-student model as a teacher who supervises students to learn and perform in an exam. Though teachers have broad knowledge of the subject, they can narrow it down to the topics required by the student to excel in their exam.
Now, with the understanding of what is knowledge distillation, we can talk about the different knowledge aspects in a teacher model that can be distilled to get a student model.
- Feature based knowledge distillation
- Response based Knowledge distillation
- Relation based knowledge distillation
Feature Based Knowledge Distillation
In order to make the parameters (Ws) in the teacher model discriminate between the features of the different objects or classes, the parameters (Ws) in the training process are learned against a loss function.
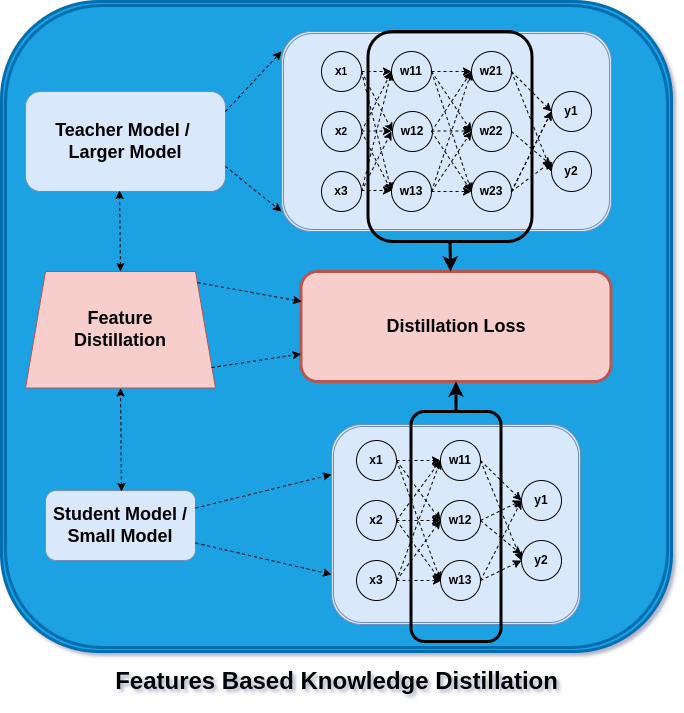
Feature Distillation
For each class, there is a set of parameters (features) that are activated, which help in predicting that object or class. These same sets of feature activations are now learned using distillation loss when training a student model. The difference between a teacher’s and a student’s model’s activation of certain features is reduced with the aid of the loss function.
Response Based Knowledge Distillation
In feature distillation, the student model is optimized for feature activation against distillation loss. In response-based distillation, the student model makes use of the teacher model’s logits to enhance its own logits.
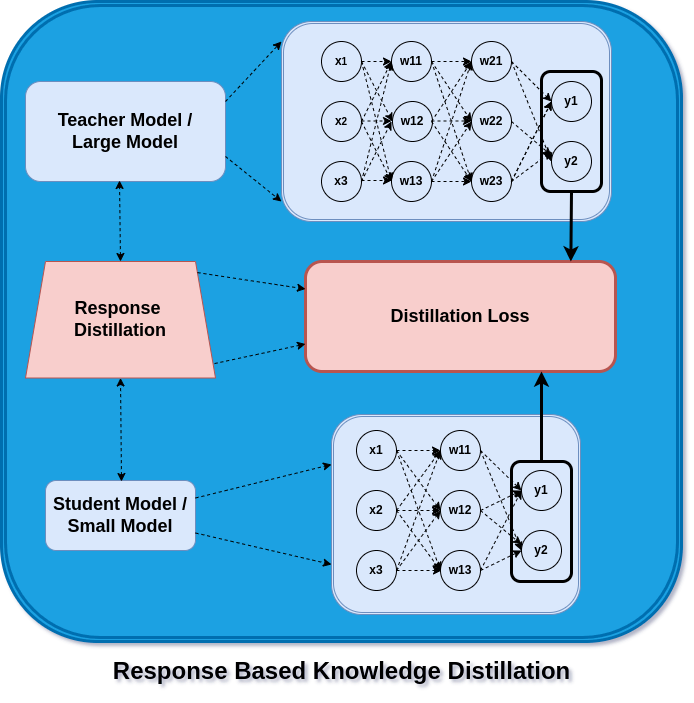
Response Distillation
Here, the distillation loss aims to capture and reduce the variation in logits between the student and teacher models. The teacher model’s predictions are mimicked as the student model gains experience through training iterations.
Relation Based Knowledge Distillation
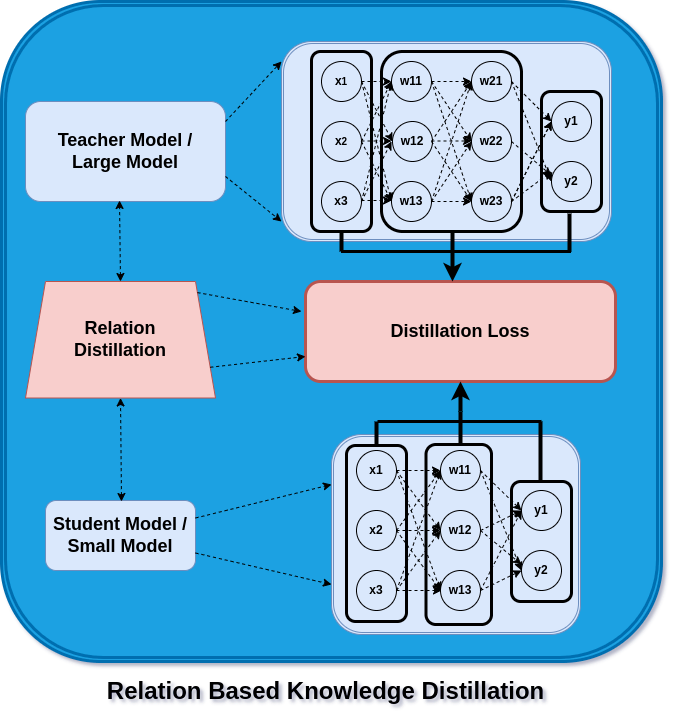
Relation Distillation
In feature and response-based knowledge distillation, the outputs from feature activation and logits are used as a leverage to build the student model. However, in this case, we use the interrelationship of the layers as input with a hidden layer or a hidden layer with output as the source of learning for the student model.
These relationships now consist of layers that can be thought of as probability distributions, similarity matrices, or feature embeddings. As a result, the student learns from the teacher’s model how to construct its embedding or distribution.
How to train a student model from teacher model?
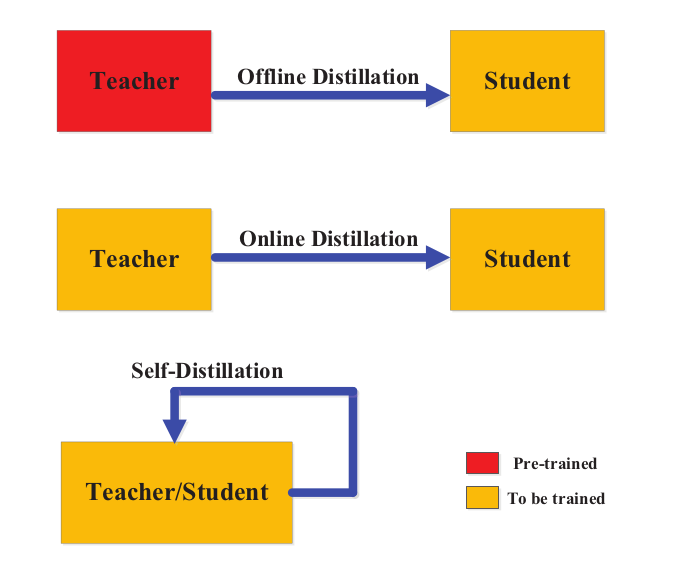
Training a student model also called as Distillation Schemes, refers to how a teacher model can distil the knowledge to a student model, whether a student model can be trained along with teacher model or not. Distillation scheme is divided into three main categories as follows
- Offline Distillation
- Online Distillation
- Self-Distillation
Distillation Schemes
Offline Distillation
Training a student model in offline mode consists of two steps
- Training a large teacher model on a set of training samples.
- Extracting knowledge from pre-trained teacher model in the form of logits or intermediate features.
Logits and intermediate features are used as guide to train a student model. Usually the first step is not considered as knowledge distillation step as it assumed to be pre-defined. Offline Distillation mainly focuses on transfer of knowledge from specific parts of the teacher model like sharing probability distribution of data in the feature space or loss function for matching features. The main advantage of offline distillation is that it is easy to implement, but the only drawback is the initial training time required for the high-capacity teacher model.
Online Distillation
Online Distillation
Though offline distillation is simple to implement, the issue remains in finding a large-capacity high performance teacher model, which is a prerequisite for offline distillation. Thus, to resolve this issue, comes the online distillation. In Online Distillation, the student and teacher model are updated simultaneously and the whole knowledge distillation is end-to-end trainable. Various works have been developed over the years like deep mutual learning, multiple neural network work in a collaborative way.
Researchers employed a online distillation to train large-scale distributed neural network, and proposed a variant of online distillation called co-distillation. Co-distillation in parallel trains multiple models with the same architectures and any one model is trained by transferring the knowledge from the other models. However, existing online methods (e.g., mutual learning) usually fails to address the high-capacity teacher in online settings.
Self-Distillation
In self-distillation, the same network is used for both the teacher and student model. In 2019, researchers proposed a self-distillation method, in which knowledge from the deeper sections of the network is distilled into its shallow sections.
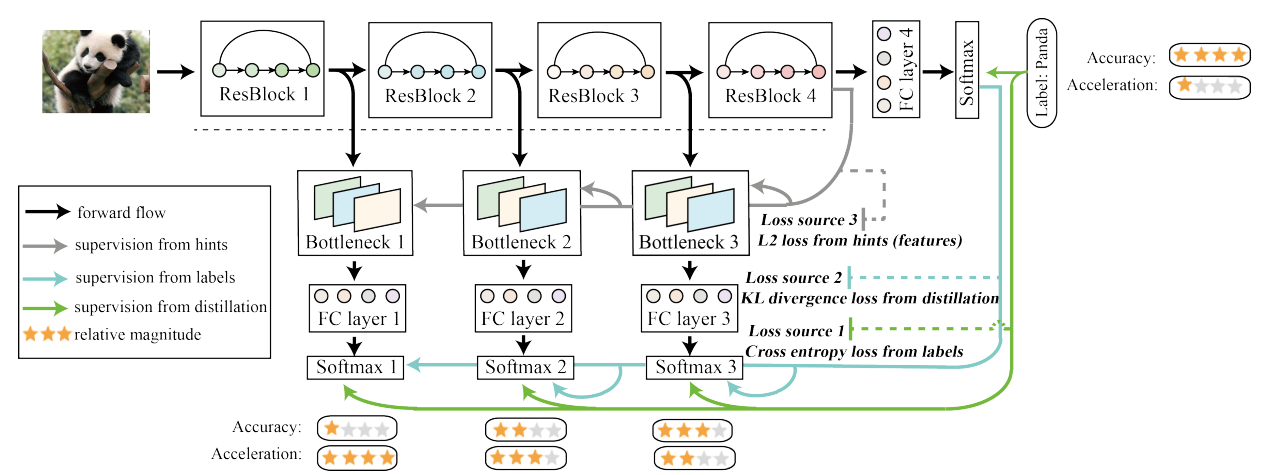
Self-Distillation: (i) A ResNet has been divided into four sections according to their depth. (ii) Additional bottleneck and fully connected layers are set after each section, which constitutes multiple classifiers. (iii) All of the classifiers can be utilized independently, with different accuracy and response time. (iv) Each classifier is trained under three kinds of supervision as depicted. (v) Parts under the dash line can be removed in inference.
Similar to self-distillation, self-attention was proposed for lane detection. The network utilizes the attention maps of its own layers as distillation targets for its lower layers. In other approach, knowledge from earlier epochs of the teacher model can be transferred to its later epochs to train the student model.
Teacher-Student Architecture
For knowledge distillation, the teacher-student architecture forms the generic carrier for knowledge transfer. The quality of knowledge acquisition and distillation from teacher to student is determined based on the design of the architecture.
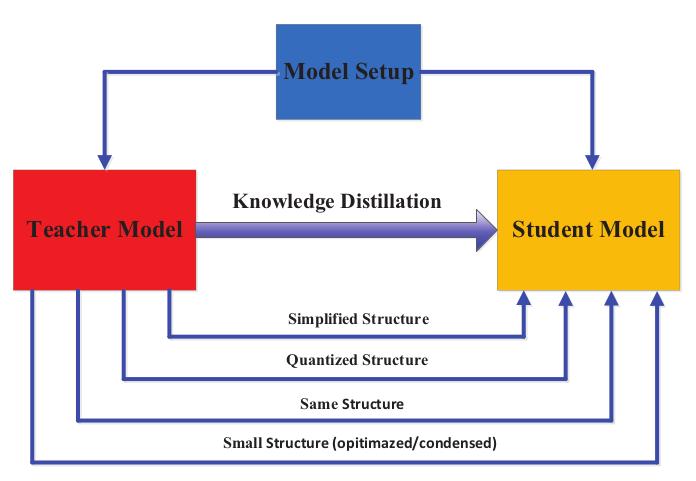
Earlier, knowledge distillation was designed to compress an ensemble of deep neural networks. The complexity of deep neural network comes from two dimension: depth and width of the neural network. And we transfer knowledge from deeper and wider neural network to shallower and thinner neural network.
Building Student Model
A student models are built as a
- Simplified version of teacher model with fewer layers and fewer neuron per layer.
- A quantized version of teacher network, in which the structure of the network is maintained.
- A small network with efficient basic operations.
- A small network with optimized global network structure.
- Network same as teacher network.
Knowledge transfer degrades as the model capacity gap between the teacher and student model increases. Thus, to effectively share the knowledge a variety of methods are proposed as a Distillation Algorithms.
- Adversarial Distillation
- Multi-Teacher Distillation
- Cross-Model Distillation
- Graph-based Distillation
- Attention based Distillation
- Data-Free Distillation
- Quantized Distillation
- Lifelong Distillation
- NAS-based Distillation
Now, each of these method is worth a separate blog post, so we’ll learn few of these distillation which are widely used.
Adversarial Distillation
GANs, generative adversarial networks contains a generator and a discriminator network, the discriminator in a GAN estimates the probability that a sample comes from the training data distribution while the generator tries to fool the discriminator using generated data samples. Inspired from this, many adversarial knowledge distillation methods are proposed to enable the teacher and student networks to have a better understanding of the true data distribution.
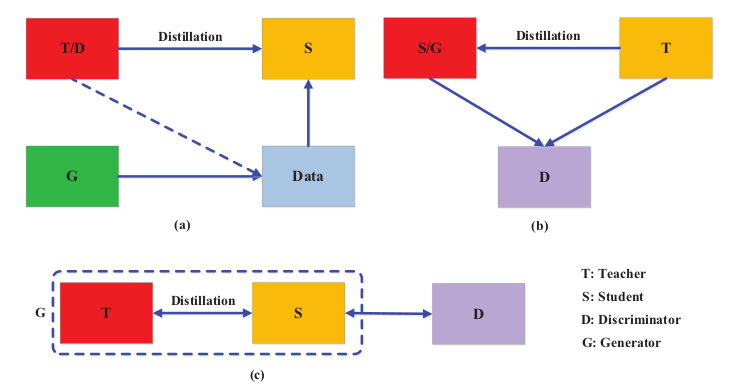
The different categories of the main adversarial distillation methods. (a) Generator in GAN produces training data to improve KD performance; the teacher may be used as discriminator. (b) Discriminator in GAN ensures that the student (also as generator) mimics the teacher. (c) Teacher and student form a generator; online knowledge distillation is enhanced by the discriminator.
Adversarial Learning is mainly divided into three categories as follows
- Building adversarial generator, that generates synthetic data either to create a training dataset or to augment the training dataset.
- To match a student model to teacher model, a discriminator is used to distinguish the samples from the student and teacher models by using logits or the features.
- Adversarial learning-based distillation technique focuses on online distillation where the student and the teacher models are jointly optimized.
Multi-Teacher Distillation
Different teacher architectures can provide their own useful knowledge for a student network. The multiple teacher networks can be individually and integrally used for distillation during the period of training a student network. In a typical teacher-student framework, the teacher usually has a large model or an ensemble of large models. To transfer knowledge from multiple teachers, the simplest way is to use the averaged response from all teachers as the supervision signal.
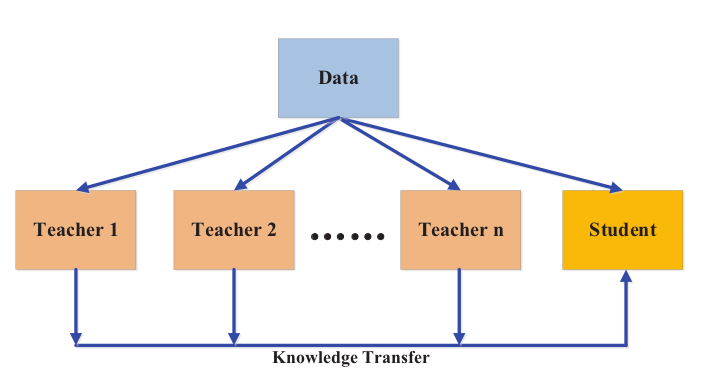
Multi-Teacher Distillation
Multiple teacher networks have turned out to be effective for training student model usually using logits and feature representation as the knowledge. In addition to the averaged logits from all teachers, we can further incorporate features from the intermediate layers in order to encourage the dissimilarity among different training samples.
Generally, multi-teacher knowledge distillation can provide rich knowledge and tailor a versatile student model because of the diverse knowledge from different teachers. However, how to effectively integrate different types of knowledge from multiple teachers needs to be further studied.
Cross-Modal Distillation
The data or labels for some modalities might not be available during training or testing. For this reason it is important to transfer knowledge between different modalities. Several typical scenarios using cross-modal knowledge transfer are reviewed as follows.
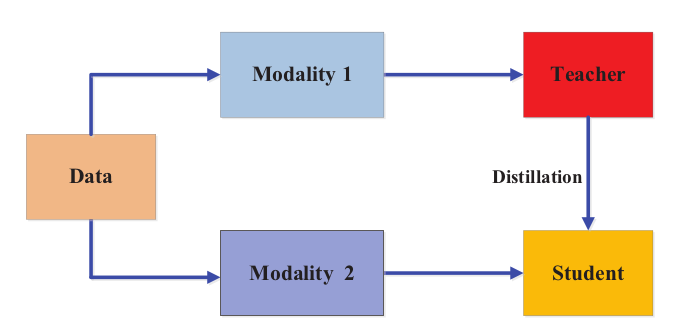
Cross-Modal Distillation
Consider a pretrained teacher model, trained on RGB images (one modality) with large number of well annotated samples, now transfer this knowledge from teacher to student model with a new unlabeled input modality, such as depth or optical flow of the image. Specifically, the proposed method relies on unlabeled paired samples involving both modalities, i.e., both RGB and depth images. The features obtained from RGB images by the teacher are then used for the supervised training of the student.
The idea behind the paired samples is to transfer the annotation or label information via pair-wise sample registration and has been widely used for cross-modal applications.
Reference
Paper: Knowledge Distillation: A Survey
...
Feedback is welcomed 💬