Why Tf-Idf is more effective than Bag-Of-Words?
Why Tf-Idf Over Bag-of-Words?
In Machine Learning, it is nice when models are simple and interpretable because it reduces the burden of debugging a complex model when things don’t work. But simple models do not always lead to the best results. Similarly, there are simple text featurizer which doesn’t result in effective models.
For text data, we should convert the text features into a numerical form. Though it is simple to convert a word into a number by mapping each word with a unique number or an identifier, it results in poor features as stopwords occur more often than keywords.
Stopwords refers to words like a, the, and, this,, and many other such words are listed under stopwords. These words don’t add any context to the sentence.
Bag-Of-Words
A naive approach to work with text data is to use Bag-of-Words. In bag-of-words, a text document is converted into a vector of counts. For instance, consider the below sentence.
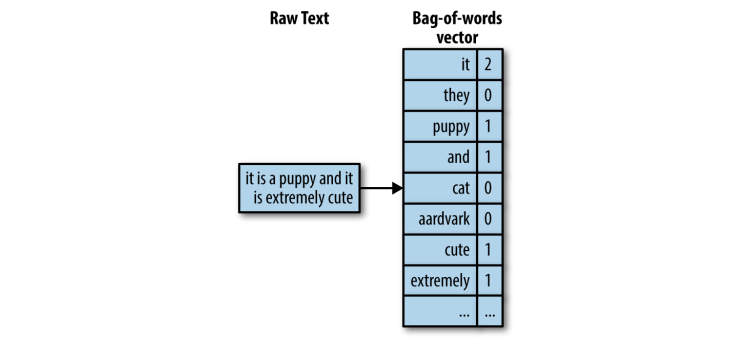
Figure 1: Turning raw text into a bag-of-words representation
Since bag-of-words approach works based on the frequency count of the words. In the above example, we can see the stopwords like it, is are occurring more than contextually relevant words like puppy and cute. To put into a data matrix, the raw text is a data point, and each word is a feature, meaning each word is one separate dimension.
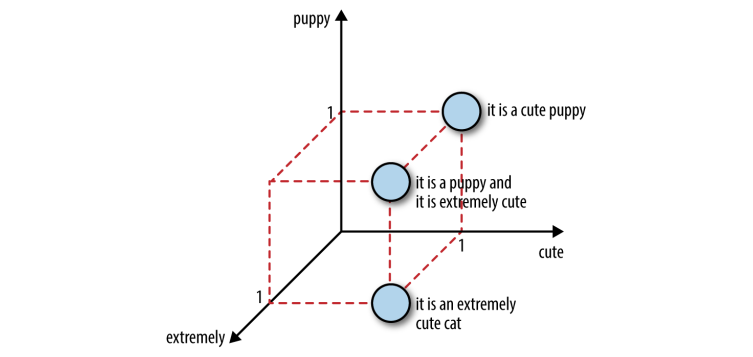
Figure 2: Three sentences in 3D feature space
An issue with the bag-of-word approach is that it loses the semantic meaning of the words. For instance, not bad semantically means decent or even good. But both the words not and bad bring negative sentiment when considered alone.
There are other approaches like Bag-of-n-Grams, which uses bigram, trigram to capture the words that occur often together. But this leads to an increase in feature space. As n increases in bag-of-n-grams, the features space becomes even more expensive to store and model upon, N(unigram) < N(bigram) < N(trigram).
We can reduce the feature space by performing a bunch of text processing techniques as follows
-
Stopwords Removal - Remove words like a, the, and, it, is, etc. It will reduce the dimension of the feature space.
-
** Frequency-based filter** - Along with stopwords, we can use a frequency count of words and remove words that occur often but adds less value to the context of the sentence.
-
Stemming - It is an NLP task that tries to chop each word down to its basic linguistic word stem form. For instance, words like swimmer, swimming, swim, will be mapped to one-word swim. Sometimes it can hurt more than it helps. For instance, the words new, news are different words, but both are stemmed to new. Stemming has computation cost, and its benefits depend on the application.
-
Chunking and Parts-of-speech tagging - These are NLP techniques used for finding meaningful words in a sentence and use them as the feature vector. It finds noun phrases and other similar details to extract keywords from a sentence.

Figure 3: Part-of-speech
All the above techniques help in reducing the feature space, but the initial step of bag-of-words acts as a downside because it emphasizes words only based on counts. To overcome this, a simple twist to bag-of-words introduces the tf-idf approach.
TF-IDF (term frequency-inverse document frequency)
Unlike, bag-of-words, tf-idf creates a normalized count where each word count is divided by the number of documents this word appears in.
N is the total number of documents. The fraction (N / (# documents in which word w appears)) is known as inverse document frequency.
Idea behind TF-IDF
If a word appears in all the documents, then its inverse document frequency is 1. Similarly, if the word appears in few documents, then its inverse document frequency is much higher than 1. Alternatively, we can take a log transform of Inverse Document Frequency. Why? Let’s see, Consider we have 10000 documents, and each of these documents has the word the. The IDF score becomes 1. Now, consider a word like market, and it appears in 100 documents, then its IDF score becomes 10000/100 = 100.
Now, on taking log transform of the IDF score, we get 0 for the word the and 2 for the word market. Thus, log transform tends to zero out all words that appear in all documents. It effectively means that the word is removed from the feature space.
Thus, Tf-idf makes rare words more prominent and effectively ignores common words. It is closely related to frequency-based filters but much more mathematically elegant than placing hard cutoff thresholds.
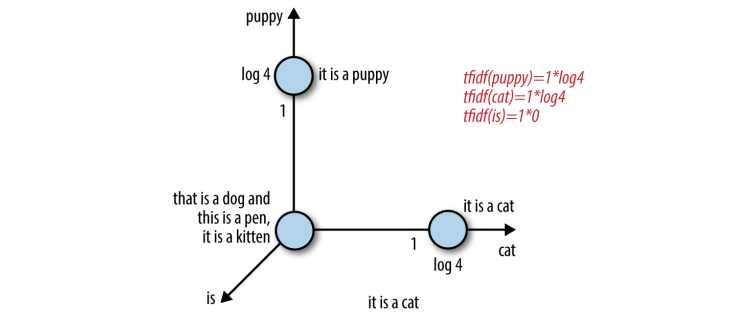
Figure 4: Tf-idf representation of the sentences
While modeling an algorithm on tf-idf feature space, it is important to use other feature reduction techniques as discussed earlier, like stemming, part-of-speech, etc, to get an effective result.
Reference
...
Feedback is welcomed 💬