SimCLR

Figure 1: Google AI Blog
What is Self-Supervised Learning?
It is a method of machine learning where the model learns from the supervisory signal of the data unlike supervised learning where separate labels are specified for each observation. It is also known as Representation Learning.
Note, the model’s learned representation is used for downstream tasks like BERT, where language models are used for text classification tasks. Here, we can use Linear classifiers along with a learned self-supervised model for prediction.
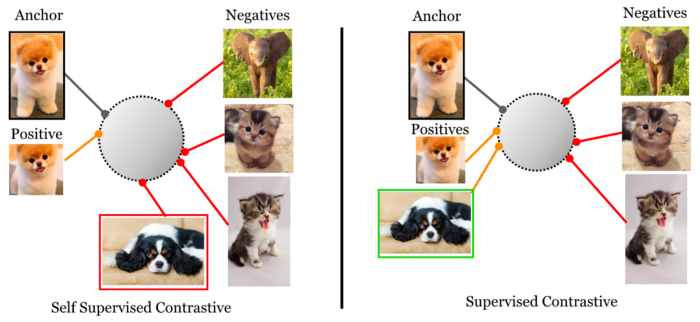
Figure 2: Google AI Blog
Why Self-Supervised Learning?
Supervised learning requires a large amount of labelled dataset to train a model. For instance, current deep learning architectures for image classification are trained on labelled ImageNet dataset, and it took years to build the dataset.
In addition, there is a vast amount of unlabelled data on the internet which the self-supervised learning can tap into, to learn the rich and beautiful representations of the data.
What is Contrastive Learning?
Contrastive Learning is a self-supervised learning approach where the model aims to learn the representation by forcing similar observations to be closer and dissimilar observations to be far apart.
Therefore, it tries to increase the contrast between dissimilar elements and reduce the contrast between the similar elements.
SimCLR: a simple framework for contrastive learning of visual representations.
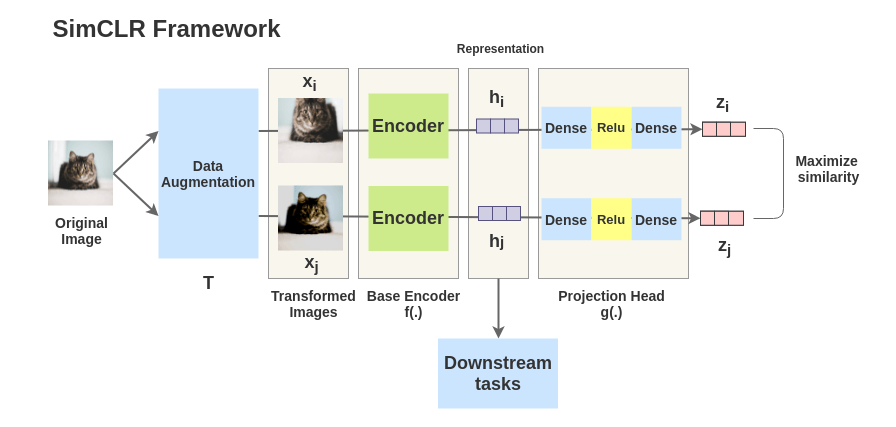
Figure 3: Amit Choudhary's Blog
Major components of SimCLR
-
Using a wide range of data augmentation techniques helps in creating effective representation.
Random Crop, Resize, Gaussian Blur, Color Distortion etc.
-
Building a learnable nonlinear model between representation and contrastive loss improves the quality of the learned representation. It is also known as a projection head.
Feedforward Network with Relu activation, g(hi).
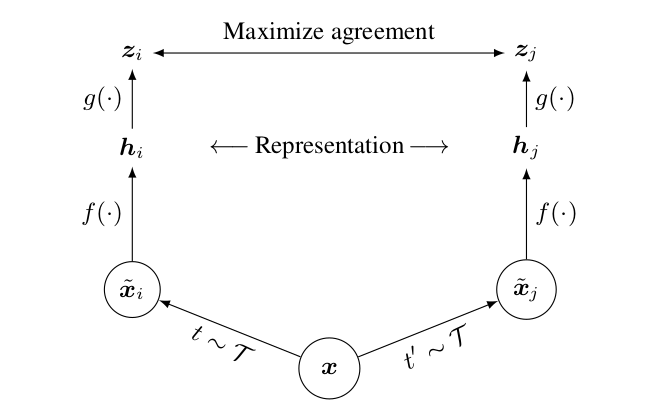
Figure 4: SimCLR Paper
-
Contrastive cross entropy loss along with temperature parameters benefits in representation learning.(TBD temperature)
-
Greater batch size and longer training benefits the model in learning effective representation.
In the above image, f(.) is the base encoder network that extracts the representation from augmented images. Authors use the ResNet (f) architecture to learn the image representation and projection head g(.) maps the representation to the contrastive loss function.
Given a positive pair of augmented images xi and xj , the contrastive prediction task tries to predict whether xj is similar to xi. Positive pair means that xi and xj belong to the same image while negative pair refers to xi and xj belonging to different images.
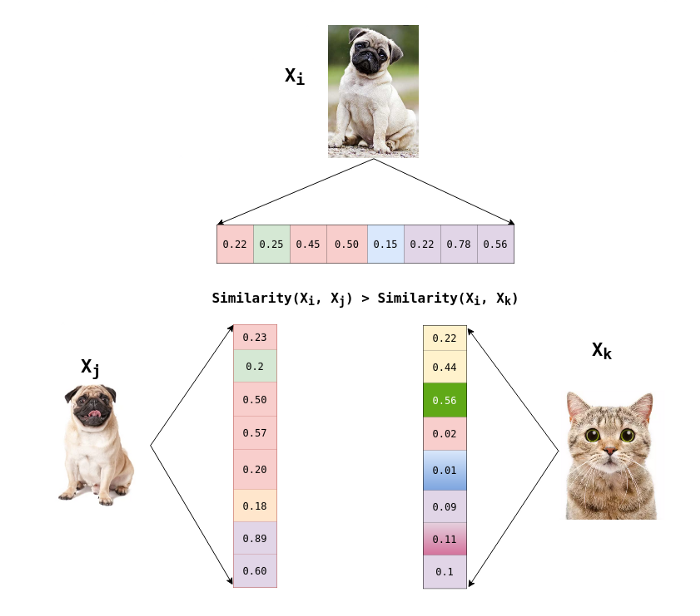
Figure 5: From Author
NCE Loss
Contrastive loss used in SimCLR is NT-Xent Loss (Normalized Temperature Scaled Cross Entropy Loss).
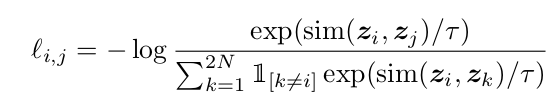
Figure 6: SimCLR Paper
𝜏 — Temperature factor
When a min-batch is selected, let’s say two, we have a total of four images after augmentation.

Figure 7: Amit Choudhary's Blog
Now, each image is scored against every other augmented image to create a softmax probability across all pairs.
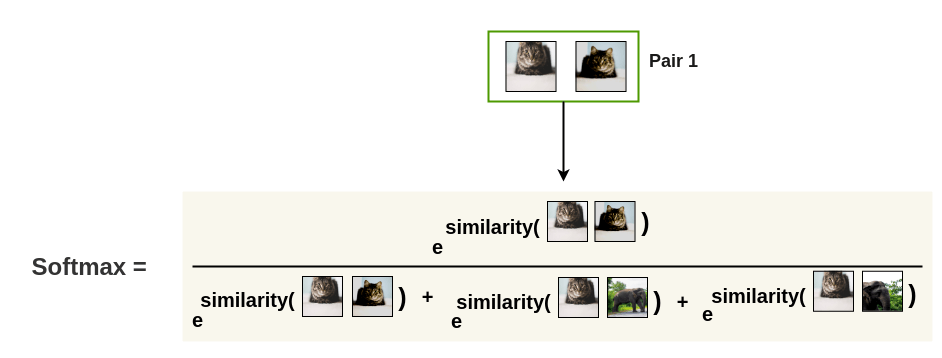
Figure 8: Amit Choudhary's Blog
We can think of the denominator as the sample space and the numerator as the probability of an event.
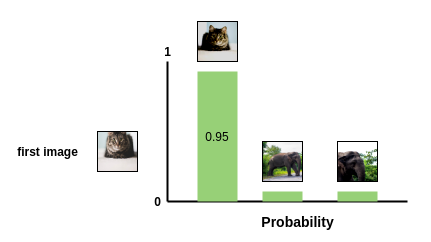
Figure 9: Amit Choudhary's Blog
In the loss function, we have temperature hyper-parameter, which needs to be tuned for effective discrimination between positive and negative pair of images. Understanding temperature value is quite a mystery with vague explanation in the paper.
As described in paper, the appropriate temperature can help the model learn from hard negatives. In addition, they showed that the optimal temperature differs on different batch sizes and number of training epochs.
I recommend reading the reference URL for temperature hyper-parameter on Reddit. It suggests, how lower value of temperature makes a wide difference between softmax result of the vector.
Note: Hard negatives are images xj, which belong to dissimilar image sets but look similar to xi, which makes it hard to find the difference between similar and dissimilar images.
For complete code: SimCLR
Conclusion
With growing research in self-supervised learning along with massive amounts of unlabelled data makes the path of self-supervised learning in computer vision a fruitful one.
If you’ve liked this post, please don’t forget to subscribe to the newsletter.
Reference
- SimCLR Paper
- Lilian Weng’s — Self-Supervised Learning
- Amit Chaudhary — Illustrated SimCLR
...
Feedback is welcomed 💬