Mixed Precision Training
What is Mixed Precision Training
Mixed precision training is a technique used in training a large neural network where the model’s parameters are stored in different datatype precision (FP16 vs FP32 vs FP64). It offers significant performance and computational boost by training large neural networks in lower precision formats.
For instance, In Pytorch, the single-precision float means float32 and by default, the parameters take float32 datatype. Now if we have a parameter (W) that could be stored in FP16 while ensuring that no task-specific accuracy is affected by this movement between precision, then why should we use FP32 or FP64?
Notations
FP16 — Half-Precision, 16bit Floating Point-occupies 2 bytes of memory.
FP32 — Single-Precision, 32bit Floating Point-occupies 4 bytes of memory.
FP64 — Double-Precision, 64bit Floating Point-occupies 8 bytes of memory.
Since the introduction of Tensor Cores in the Volta and Turing architectures (NVIDIA), significant training speedups are experienced by switching to mixed-precision — up to 3x overall speedup on the most arithmetically intense model architectures.
The ability to train deep learning networks with lower precision was introduced in the Pascal architecture and first supported in CUDA® 8 in the NVIDIA Deep Learning SDK.
Why MPT is important
- Requires less memory, enabling training and deploying large neural networks.
- Transfer is faster since the bandwidth required is reduced for the transmission of data.
FP16 requires 2 bytes, as the number of bytes is reduced to capture the same numerical entity, it reduces the amount of memory required to train a model and helps in increasing the batch size for our training. And also the data transfer of type FP16 is faster compared to FP32 and FP64.
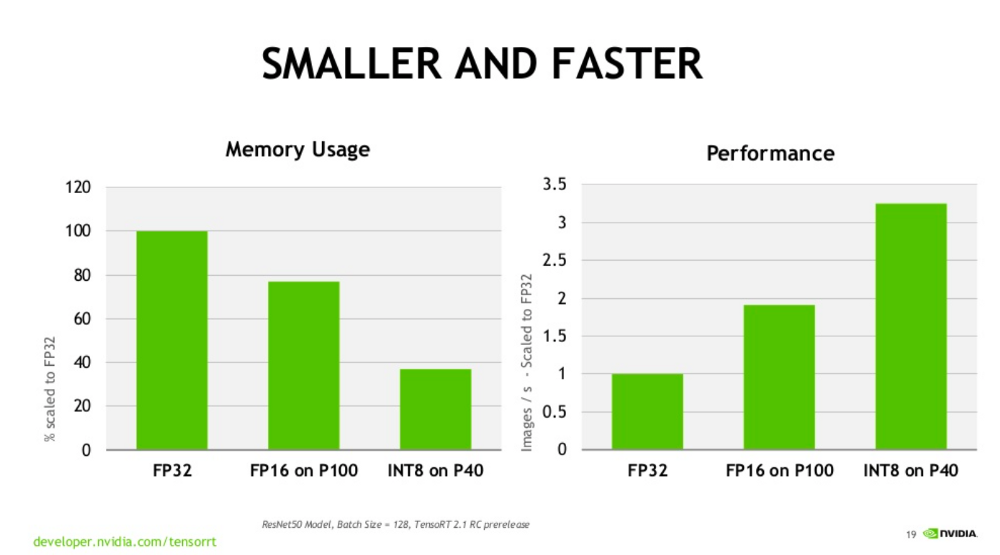
Figure 1: Smaller Vs Faster
For 1 million parameters
1. FP32 — 1000,000 * 4 Bytes — 4 MB
2. FP16 — 1000,000 * 2 Bytes — 2 MB
Though it’s half the amount of memory in FP16, few folks many consider 2MB is not worth the headache for moving to mixed-precision, then
Consider the following situation of using Resnet50, The 50-layer ResNet network has ~26 million weight parameters and computes ~16 million activations are in the forward pass. If you use a 32-bit floating-point value to store each weight and activation this would give a total storage requirement of 168 MB. By using a lower precision value to store these weights and activations we could halve or even quarter this storage requirement, i.e. for 42 million transactions, FP16 requires 84MB.
There is a significant improvement in memory required for the same number of parameters.
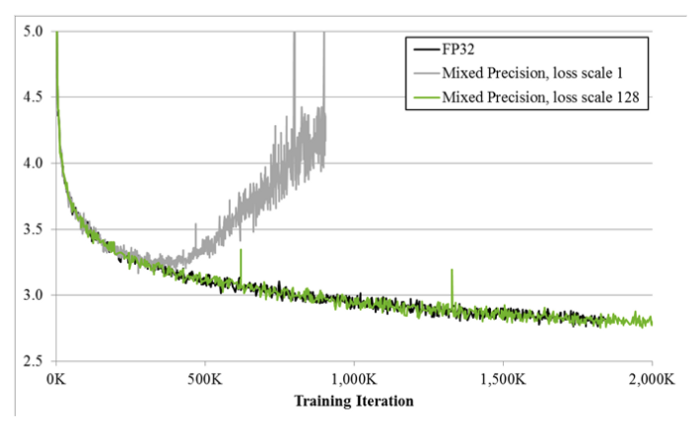
Figure 2: Training Iteration
Steps in Mixed Precision Training
- Porting the model to use FP16 wherever possible.
- Adding loss scaling to preserve small gradient values.
The first point, Porting model to use FP16 is simple, we access the model parameters and move it float16 or half-precision as widely known. It is similar to changing the dtype of a variable.

Figure 3: Paper
The second point, Adding loss scaling to preserve small gradient values, refer to scaling the parameter by multiplying alpha value to it, before backpropagation and then unscale it by dividing the gradient by alpha before updating the weight. Loss scaling is done to avoid the gradient exploding/vanishing.
Interestingly, there is adaptive scaling technique is introduced for a layer-wise update of parameters by alpha.
What happens when we switch to Mixed Precision
- Decreased memory usage to train and deploy large models.
- Less time required for inference, execution time can be sensitive to memory or arithmetic bandwidth. Half-precision halves the number of bytes accessed, thus reducing the time spent in memory-limited layers.
Nvidia GPUs offer up to 8x more half-precision arithmetic throughput when compared to single-precision, thus speeding up math-limited layers. The term Mixed Precision Training is realized because the training utilizes both the half-precision and single precision representations.
How Mixed Precision works
Based on research, certain operations tend to cause over or underflow of a parameter or a variable, and some act intact within FP16, ultimately a few lists are generated like AllowList, DenyList, and InferList, which mentions which ops should take place with FP16 and vice-versa.
AllowList operations are operations that take advantage of GPU Tensor Cores. DenyList operations are operations that may overflow the range of FP16, or require the higher precision of FP32. InferList operations are operations that are safely done in either FP32 or FP16. Typical ops included in each list are:
- AllowList: Convolutions, Fully-connected layers.
- DenyList: Large reductions, Cross entropy loss, L1 Loss, Exponential.
- InferList: Element-wise operations (add, multiply by a constant).
Automatic Mixed Precision
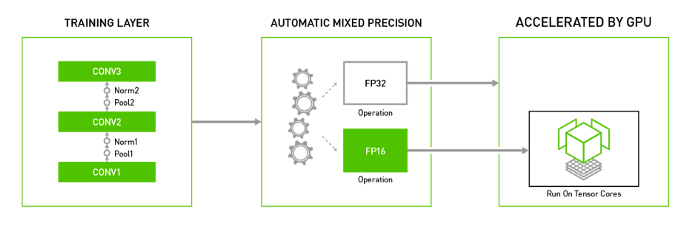
Figure 4: AMP
With recent updates in deep learning frameworks, a technique called Automatic Mixed Precision has been introduced. It helps the developers in performing these casting and scaling operations automatically
- Automatic loss scaling and master weights integrated into optimizer classes.
- Automatic casting between float16 and float32 to maximize speed while ensuring no loss in task-specific accuracy.
In those frameworks with automatic support, using mixed precision can be as simple as adding one line of code or enabling a single environment variable. Currently, the frameworks with support for automatic mixed-precision are TensorFlow, PyTorch, and MXNet.
Pytorch AMP
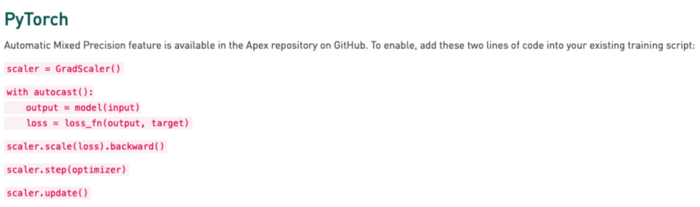
Figure 5: Pytorch - AMP
Note, Nvidia’s tensor cores are designed in such a fashion that keeping the dimension of the matrix as a multiple of 8 helps in the faster calculation. Do read NVIDIA’s Mixed Precision article to understand,
- How to set the dimension in CNN.
- How to choose a mini-batch size.
- How to choose a linear layer.
- How to pad the vocabulary in a sequence-based model.
Details related to How to set the alpha value, How to scale & unscale a parameter, how the performance is affected if a poor scaling factor is chosen, how to match the performance of FP32 using FP16, check out the reference link to NVIDIA Mixed Precision.
If you’ve liked this post, please don’t forget to subscribe to the newsletter.
References
Loss Scaling while training in Mixed Precision
Review on paper
Nvidia’s Mixed Precision
Pytorch AMP
...
Feedback is welcomed 💬